
Generating Automatic Alt-Text with the Bacalhau Bluesky Bot
(4:10) Using the latest in Large Vision Models (LLaVa), we've built a Bluesky Bot which can generate alt-text for any image in seconds with Bacalhau


At the Bacalhau Project, we're driven by community. We love hearing your thoughts, as well as the wider conversations that they inspire. Recently, we've been actively engaged in the Bluesky community and their amazing optimism and flow of ideas. It's a great platform to build on!
In December, we launched the Bacalhau Bluesky Bot that enabled people to spin up distributed jobs on a Bacalhau network with a simple post. We then extended it to showcase some of Bacalhau's edge capabilities by building in image classification. We also included a fun (and educational!) feature hotdog/not hotdog.
Today, we're building on that success with a brand-new bot that we hope will make the web a little more accessible; An automatic alt-text generation bot, powered by Bacalhau and the LLaVa LVM (Large Vision Model).
You can check it out at @alt-text.bots.bacalhau.org
What have we built?
As of right now, you can use our latest Bluesky bot @alt-text.bots.bacalhau.org to automatically generate alt-text for images in a Bluesky post. It is simple to use. If you find an image on Bluesky that doesn't have alt-text, reply to that post with @alt-text.bots.bacalhau.org and the Bacalhau Bluesky alt-text bot will automatically pull that image and use LLaVa to generate alt-text for it.
Why did we build it?
The web is a visual medium, but it's not experienced the same way by everyone. Those with visual impairments must experience the web through other tools, such as screen readers, which describe what's on the screen and enable them to interact with the elements of a page.
From a technical standpoint, text elements are easy to work with. Computers are really good at parsing text and making sense of it - whether it's finding a keyword, filtering button labels, or just reading text aloud.
Images present a more difficult challenge. Computers and software do not interpret images and rich media content with the same ease as they do with text.
For instance, when you or I look at a picture, we instantly recognize the rolling hills or fluffy cat or whatever is in it. But to a computer, an image is an array of RGB values that are stored, retrieved, and rendered in a particular order within a defined set of bounds. A screen reader does not know that a value like [ [123, 55, 88], [09, 01, 91], [18, 243, 6] ... ] is actually a picture of the moon, the sky, or the sea.
One of the remedies to this dilemma is alt-text, which describes in plaintext what an image contains, so that people using screen readers and other similar tools aren’t excluded.
But despite being available since 1993, not everybody adds alt-text to their images. Whether it's not knowing how to add it, being unaware of the need for it, or simply not caring is up for debate. But the issue stands: alt-text is a super-valuable feature that broadens the reach and utility of the web.
Why is this still hard?
Over the past few decades researchers have developed advanced new methods for interpreting images and rich media in a way that's closer to human perception. One of the biggest advances that has crept into almost every app we use is Convolutional Neural Networks (CNNs). CNNs are able to examine the pixel values of an image, group them together, and find patterns that provide insight into its content. CNNs can then add labels to the items in the image.
CNNs are great if you want to, say, identify which images have cars, oranges, or trees in them. They can also count how many of a given item are in an image. These abilities are not very useful for providing context to that image. It's one thing to know that a picture has some people in it. It's another thing to recognise the iconic image of "Lunch Atop a Skyscraper".

Enter the LVM
One of the more interesting things to come out of the explosion of Large Language Models (LLMs) over the last few years is Large Vision Models (LVMs). At their simplest, they are LLMs that have been augmented with a visual encoder that enables them to interpret an image and output rich descriptions of the content therein. LVMs are a great step forward for automating the generation of alt-text for images.
While human-written alt-text is always preferred, LVMs can automate the process of writing descriptive text with a much higher fidelity than a simple image classifier.
How does it work?
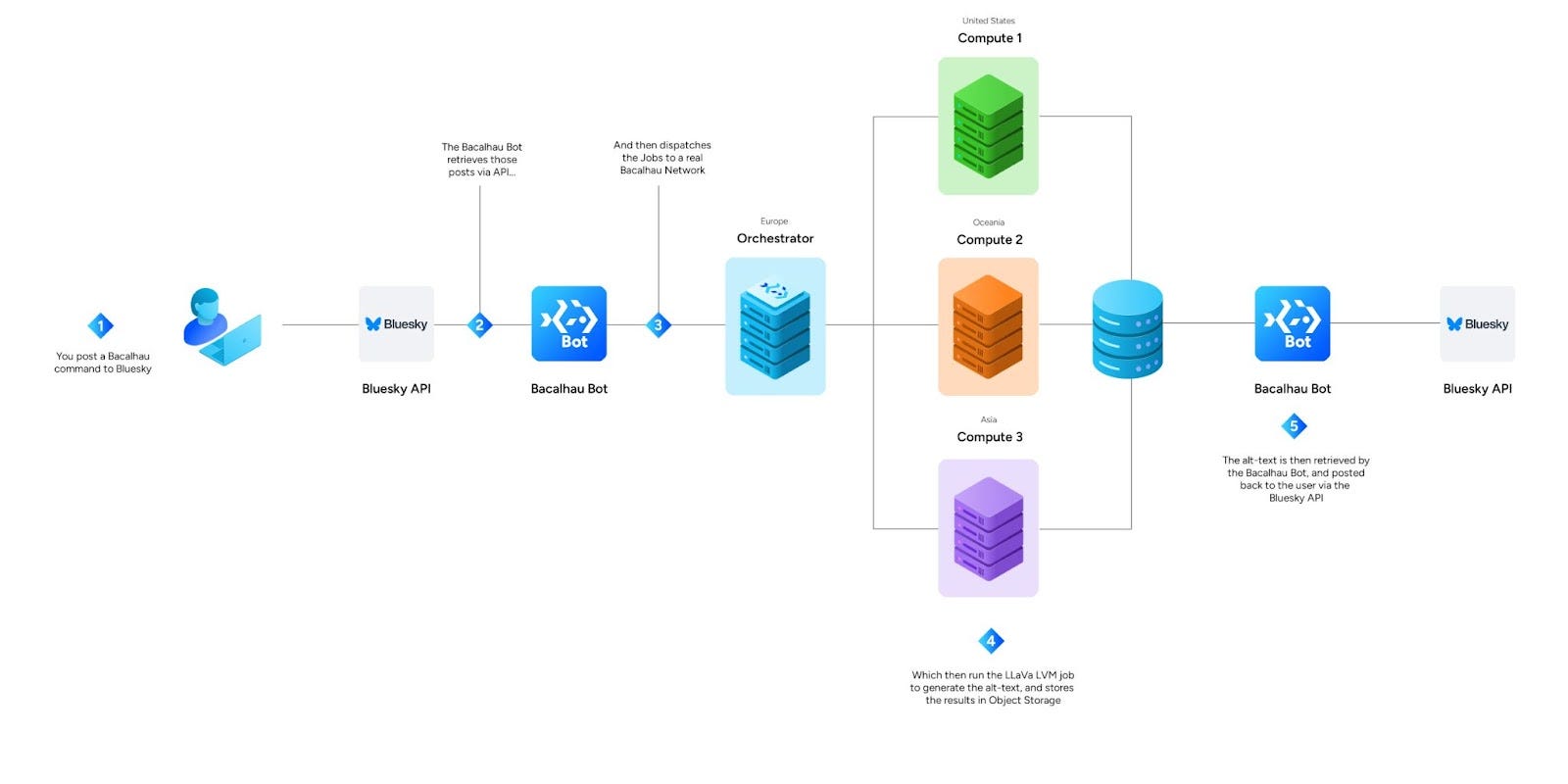
When you mention @alt-text.bots.bacalhau.org in a thread, the Bacalhau Bluesky bot automatically retrieves the post you’ve replied to and looks for all of the images in that post. The bot then takes all of the URLs for those images and creates a job on a private Bacalhau network with some GPU-enabled instances, backed by Expanso Cloud.
The managed orchestrator in Expanso Cloud identifies the nodes on the network that are available to run the LVM, and then distributes that job to those nodes. Once the job arrives, it downloads those image files from the list of URLs and runs them through LLaVa to generate the alt-text. It then stores the results in an S3 bucket, and execution stops.
Meanwhile, the alt-text bot pings the Bacalhau network every few seconds for updates to the jobs’ status. Once the bot sees that the alt-text has been generated, it pulls those results and replies to the original @alt-text.bots.bacalhau.org post with the LLaVa-generated alt-text.
Conclusion
We built the Bacalhau Bluesky bot for a reason. We want to show how easy and powerful Bacalhau can be for building and deploying applications that solve real problems in next-to-no time. We also believe that the web should be for everyone, and if we can build and support a tool that widens its access, then we're always happy to do it. Finally, our bot is a call-to-action for people to add alt-text to their images! LLaVa is great, and it’s a huge step up from the tooling available even five years ago - but nothing beats the human touch.
In the meantime, give it a go!
Get Involved!
Expanso’s tools and templates make it easy to get started. Check out our public GitHub repository for examples and guides, and join the conversation on social media with #ExpansoInAction.
Have a unique use case? We’d love to hear about it! Share your projects and ideas, and let’s build the future of distributed systems together.
There are many ways to contribute and get in touch, and we’d love to hear from you! Please reach out to us at any of the following locations.
Commercial Support
While Bacalhau is open-source software, the Bacalhau binaries go through the security, verification, and signing build process lovingly crafted by Expanso. You can read more about the difference between open-source Bacalhau and commercially supported Bacalhau in our FAQ. If you would like to use our pre-built binaries and receive commercial support, please contact us!



