
Unified Data Log Insights: Leveraging Bacalhau and Motherduck for Advanced File Querying Across Distributed Networks

In this demo we have a series of different machines on Google Cloud all continuously collecting individual logs. Our key challenge lies in filtering security-related logs before consolidating the data into a central repository for detailed analysis. To address this, we've deployed a robust solution using Bacalhau layered on Motherduck. Bacalhau, a truly decentralized and distributed network, offers flexibility and scalability in handling vast amounts of data. Coupled with a service like Motherduck which connects directly with DuckDB, it allows us to efficiently collect the required data. This connection to DuckDB is established regardless of whether you have it pre-installed or running within a containerized environment, as in our setup below.
We'll guide you through our integrated approach and demonstrate how Bacalhau and Motherduck can optimize log file filtration and data collection.
Find the documentation in GitHub here and follow through step-by-step on how to do this via video here:
The Problem
The machines producing logs in this example are generating a lot of raw data, not all of it is useful to us. Therefore, we want to be able to filter it so we can centralize only the data relating to security.

If we don’t filter unnecessary data before centralizing it for further analysis, this will be costly both from a data egress and ingress perspective and from a storage perspective. To tackle this, our strategy involves deploying a Motherduck container across every machine in our network, in this context, all machines are hosted on Google Cloud.
Filtering Logs Across One Node
To start we will do this across a single machine. Within the job.yaml file we will include the node we want to select — in this case europe-west4-b. We are also going to run a python script which talks to Motherduck. We will process a single log which selects from the log data the information containing the [SECURITY] key word. We will also use a Motherduck container to run and execute this job:
Spec:
NodeSelectors:
- Key: zone
Operator: "="
Values:
- europe-west4-b
EngineSpec:
Params:
EnvironmentVariables:
- INPUTFILE=/var/log/logs_to_process/aperitivo_logs.log.1
- QUERY=SELECT * FROM log_data WHERE message LIKE '%[SECURITY]%' ORDER BY '@timestamp'
Image: docker.io/bacalhauproject/motherduck-log-processor:1.1.6
WorkingDirectory: ""
Type: dockerWe can run the Yaml file above using the following:
cat job.yaml| bacalhau createBacalhau will then reach out over the network, download the container and run that DuckDB select query against the local device.
To see the job outputs all you need to do is run:
bacalhau describe [JOB_ID]In the outputs you should also see that it is connected to Motherduck. Now, if you go over to the Motherduck app and run the job in the user interface, you can see where there had previously been no data is now populated with 187 rows:

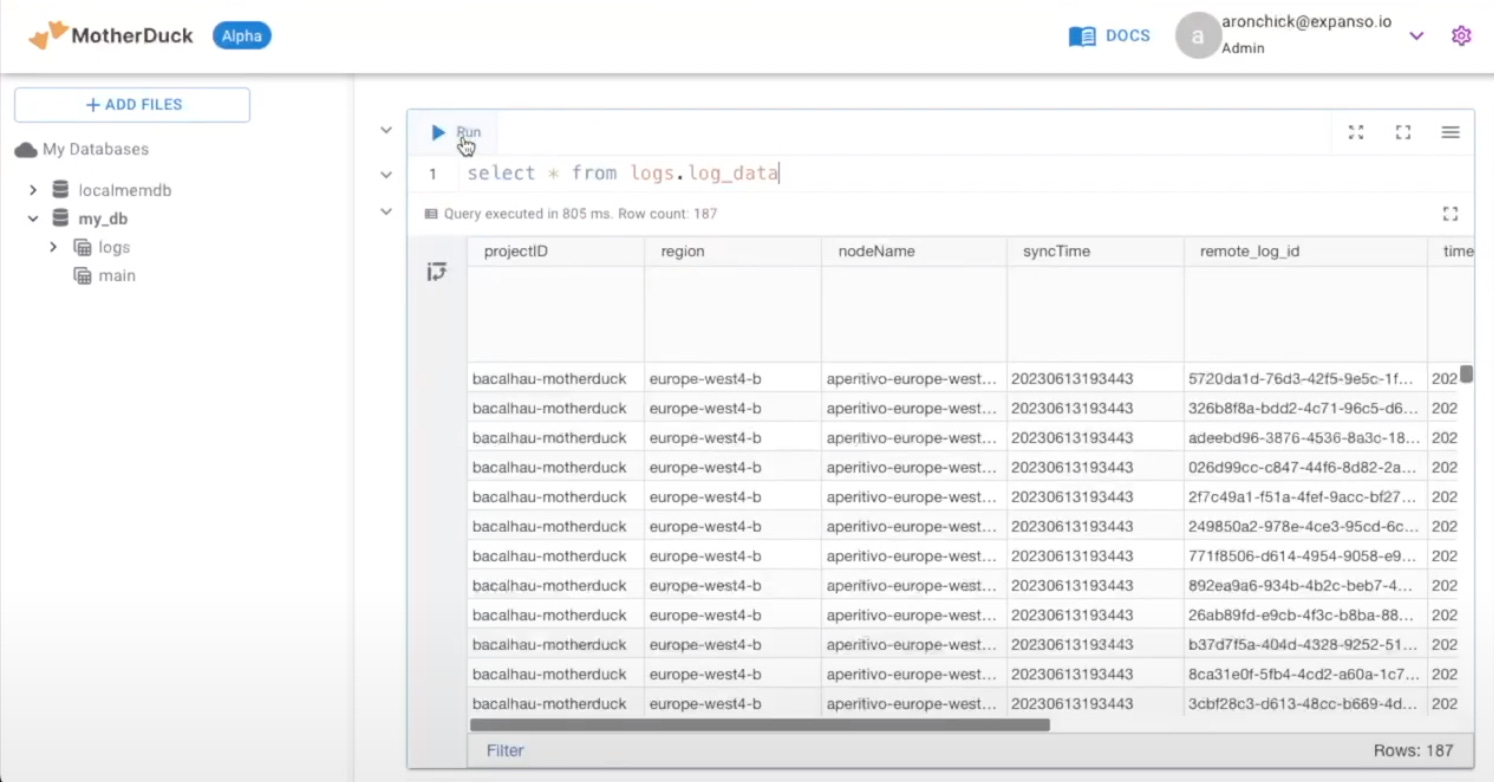
Filtering Logs Across Many Nodes, Concurrently!
Filtering across one node is relatively straightforward, and this simplicity is maintained even when scaling up to multiple nodes in a distributed network with Bacalhau. In this case we're going to run against 16 zones, simultaneously. We use almost the exact same query in our Yaml file as we use for one node, except now we use the Concurrency and TargetingMode flag:
Spec:
Deal:
Concurrency: 1
TargetingMode: true
EngineSpec:
Params:
EnvironmentVariables:
- INPUTFILE=/var/log/logs_to_process/aperitivo_logs.log.1
- QUERY=SELECT * FROM log_data WHERE message LIKE '%[SECURITY]%' ORDER BY '@timestamp'
Image: docker.io/bacalhauproject/motherduck-log-processor:1.1.6
WorkingDirectory: ""
Type: dockerWhen we task Bacalhau with this job, it reaches out to every node in the network through peer-to-peer communication. It then executes the DuckDB query against the local log file. Looking into the details of this job, you'll notice it has produced many results. When we return to the Motherduck application, we can observe a substantial increase in data: the initial 187 rows have now expanded to over 3,000.
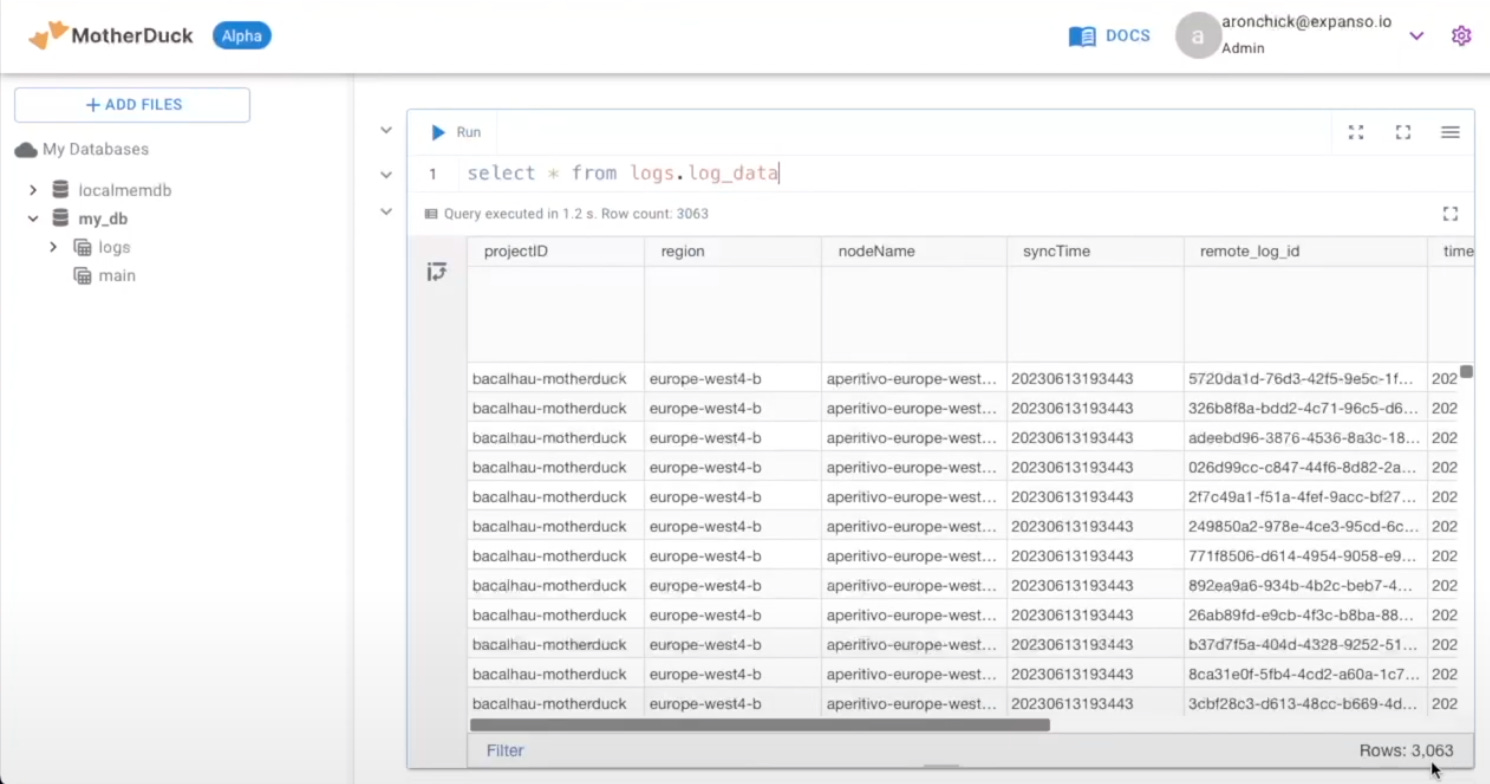
This demo shows the seamless integration between a fully decentralized and distributed network like Bacalhau and a versatile service like Motherduck. Motherduck's ability to directly connect with DuckDB and collect essential data is key. Remarkably, this holds true whether DuckDB is pre-installed, or as in our case, running within a container. This collaboration unlocks immense potential for effective and flexible data management.