
Hands-On With the 1.4.0 API
(05:18)


We’ve reached the end of our 5 Days of Bacalhau, and what a journey it has been! We’ve explored new features and have shared insights that we hope have inspired you. To finish strong, we’re diving into practical examples of how the updated Bacalhau APIs can transform your workflows.
Our Commitment to API-First
At Expanso, our API-first approach means every feature is designed with the API at its core. This ensures that our SDK and CLI are built on a solid, consistent foundation, empowering you to innovate with confidence. So, let’s take it for a spin!
You can follow this piece along in your own preferred environment, or use our Jupyter Notebook to explore the examples step-by-step. You can also follow the full guide with all the commands in our Documentation on API best practices.
Exploring Node Information
To truly harness the power of your network, you need visibility into your nodes. You need to know how many nodes you have, where they are, and what they can do. You can get all this information from the /api/v1/orchestrator/nodes endpoint at the IP address/URL of our Requester node.
import os
import requests
import pprint
REQUESTER_HOST = os.getenv("BACALHAU_API_HOST", "bootstrap.production.bacalhau.org")
REQUESTER_API_PORT = os.getenv("REQUESTER_API_PORT", "1234")
REQUESTER_BASE_URL = f"http://{REQUESTER_HOST}:{REQUESTER_API_PORT}"
response = requests.get(f"{REQUESTER_BASE_URL}/api/v1/orchestrator/nodes")
if response.status_code == 200:
pprint.pprint(response.json())
else:
print(f"Failed to retrieve nodes. HTTP Status code: {response.status_code}")
print(f"Response: {response.text}")This should output something like the following:
{
'NextToken': '',
'Nodes': [{'Connection': 'CONNECTED',
'Info': {
'BacalhauVersion': {
'BuildDate': '0001-01-01T00:00:00Z',
'GOARCH': '',
'GOOS': '',
'GitCommit': '',
'GitVersion': ''
},
'ComputeNodeInfo': {
'AvailableCapacity': {'CPU': 12.8,
'Disk': 1676877044121,
'Memory': 53930662297
},
'EnqueuedExecutions': 0,
'ExecutionEngines': ['wasm', 'docker'],
'MaxCapacity': {
'CPU': 12.8,
'Disk': 1676877044121,
'Memory': 53930662297
},
'MaxJobRequirements': {
'CPU': 12.8,
'Disk': 1676877044121,
'Memory': 53930662297
},
'Publishers': ['local','ipfs','noop','s3'],
'QueueCapacity': {},
'RunningExecutions': 0,
'StorageSources': ['inline','s3','ipfs','urldownload']},
'Labels': {
'Architecture': 'amd64',
'Operating-System': 'linux',
'owner': 'bacalhau'
},
'NodeID': 'QmPLPUUjaVE3wQNSSkxmYoaBPHVAWdjBjDYmMkWvtMZxAf',
'NodeType': 'Compute'
},
'Membership': 'APPROVED'},
…
]
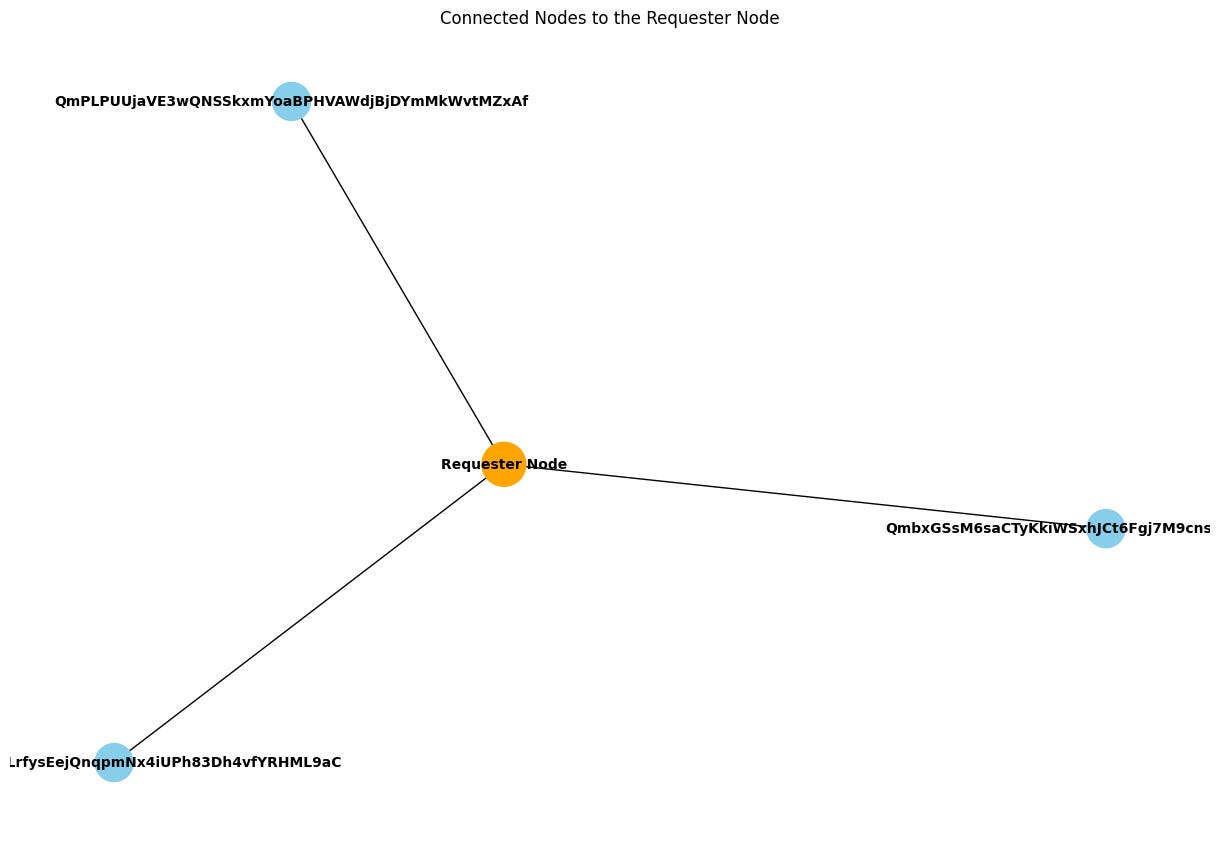
}But JSON structures aren’t always the best way to visualize complex systems. Fortunately, we’re working with Python! So, we can use Matplotlib to render out our Bacalhau network structure for us!
In the Jupyter Notebook we’ve provided, rendering out graphics is simple!
Run the following cell:
pip install networkx
pip install matplotlibAnd then run the cell that follows it:
import matplotlib.pyplot as plt
import networkx as nx
G = nx.Graph()
# Function to truncate NodeID to only show up to the second hyphen
def truncate_node_id(node_id):
parts = node_id.split('-')
return '-'.join(parts[:2]) if len(parts) > 3 else node_id
# Find the requester node
requester_node = None
for node in nodes_data['Nodes']:
if node['Info']['NodeType'] == 'Requester':
requester_node = truncate_node_id(node['Info']['NodeID'])
break
if requester_node is None:
requester_node = 'Requester Node' # Fallback in case no requester node is found
G.add_node(requester_node, label=requester_node)
# Add the connected nodes
for node in nodes_data['Nodes']:
if node['Connection'] == 'CONNECTED':
truncated_node_id = truncate_node_id(node['Info']['NodeID'])
G.add_node(truncated_node_id, label=truncated_node_id)
G.add_edge(requester_node, truncated_node_id)
# Plot the graph
plt.figure(figsize=(12, 8))
pos = nx.spring_layout(G) # positions for all nodes
labels = nx.get_node_attributes(G, 'label')
# Draw the nodes with customized colors and sizes
node_colors = ['orange' if node == requester_node else 'skyblue' for node in G.nodes()]
node_sizes = [1000 if node == requester_node else 750 for node in G.nodes()] # Reduce size by 50%
nx.draw(G, pos, labels=labels, with_labels=True, node_size=node_sizes, node_color=node_colors, font_size=10, font_weight='bold')
plt.title('Connected Nodes to the Requester Node')
plt.show()Here, we’re using the networkx module to generate a graph of the connections between our Requester and Compute nodes. We then use matplotlib to create a graphical representation of each node, and render them and their connections to a graphic.
Once that cell completes running, we’ll get a handy graph showing all of our nodes, and which Requester Nodes our Compute Nodes are connected to!
Creating a Job
Now that we know what nodes we have, what they’re capable of, and how they’re connected to each other, we can start to think about scheduling Jobs.
The simplest Job type that can be executed on a Bacalhau network is a “batch” Job. This Job runs on the first instance that becomes available to execute it, so there’s no need to worry too much about concurrency or parallelism at this point.
To create a Job and execute it via the API, you can run the following code:
import requests
import pprint
import json
job = '''
{
"Job": {
"Name": "test-job",
"Type": "batch",
"Count": 1,
"Labels": {
"foo": "bar",
"env": "dev"
},
"Tasks": [
{
"Name": "task1",
"Engine": {
"Type": "docker",
"Params": {
"Image": "ubuntu:latest",
"Entrypoint": [
"echo",
"hello, world"
]
}
},
"Publisher": {
"Type": "noop"
}
}
],
"CreateTime": 1234
}
}
'''
createJobResp = requests.put(REQUESTER_BASE_URL + "/api/v1/orchestrator/jobs", json=json.loads(job))
createJobRespData = None
if createJobResp.status_code == 200:
# Parse the JSON response
createJobRespData = createJobResp.json()
pprint.pprint(createJobRespData)
else:
print(f"Failed to retrieve nodes. HTTP Status code: {createJobResp.status_code}")
print(f"Response: {createJobResp.text}")Once that request completes, the createJobRespData variable will have a value something like the following:
{
"EvaluationID":"bb338a13-6abd-4c3f-b0dc-0842117cc95c",
"JobID":"j-9c2894ba-106f-4140-87f8-6279a1d07035",
"Warnings":[
"job create time is ignored when submitting a job"
]
}Getting Your Job Details
Now that we’ve submitted a Job, it would probably be helpful to get the results of that execution. And it’s super simple to do so! All we need is to pass the value of the JobID key that we received once we created our job to the /api/v1/orchestrator/jobs/{job_id}/results endpoint.
Add the following code to the end of the last block:
job_id = createJobRespData["JobID"]
pprint.pprint(job_id)
createJobResp = requests.get(f"{REQUESTER_BASE_URL}/api/v1/orchestrator/jobs/{job_id}/results")
if createJobResp.status_code == 200:
# Pretty print the JSON data
pprint.pprint(createJobResp.json())
else:
print(f"Failed to retrieve nodes. HTTP Status code: {createJobResp.status_code}")
print(f"Response: {createJobResp.text}")You should get something like this:
{'Items': [], 'NextToken': ''}But wait! Where are our results? When we created our job, we didn’t specify a publisher to send our results to. This doesn’t doesn’t mean that we span one up for nothing, though. The output of each Job is still stored in our network, and we can retrieve those by accessing our Job executions.
Retrieving Your Results
Retrieving our Job executions is very similar to retrieving our Job results. This time, we hit the /api/v1/orchestrator/jobs/{job_id}/executions endpoint instead.
Append the following code to the last block we executed:
getJobExecResp = requests.get(f"{REQUESTER_BASE_URL}/api/v1/orchestrator/jobs/{job_id}/executions")
getJobExecRespData = None
if getJobExecResp.status_code == 200:
# Pretty print the JSON data
pprint.pprint(getJobExecResp.json())
getJobExecRespData = getJobExecResp.json()
for item in getJobExecRespData.get("Items", []):
print(f"Execution ID: {item['ID']}")
if item["RunOutput"] != None:
print("Stdout:")
print(item["RunOutput"]["Stdout"])
print("-" * 20) # Separator for readability
else:
print(f"No data returned at this point for execution {item['ID']}")
else:
print(f"Failed to retrieve nodes. HTTP Status code: {createJobResp.status_code}")
print(f"Response: {createJobResp.text}")
And when you run the code again, you should receive something like the following:
{'Items': [{'AllocatedResources': {'Tasks': {}},
'ComputeState': {'Message': 'Accepted job', 'StateType': 7},
'CreateTime': 1720199565754869770,
'DesiredState': {'Message': 'execution completed', 'StateType': 2},
'EvalID': '851e4f04-2a6c-438f-88f7-b25e112d6fa2',
'FollowupEvalID': '',
'ID': 'e-b7e4f88c-f1b9-45fa-b3b9-34f1287beb32',
'JobID': 'j-9c2894ba-106f-4140-87f8-6279a1d07035',
'ModifyTime': 1720199566104519761,
'Name': '',
'Namespace': 'default',
'NextExecution': '',
'NodeID': 'QmbxGSsM6saCTyKkiWSxhJCt6Fgj7M9cns1vzYtfDbB5Ws',
'PreviousExecution': '',
'PublishedResult': {'Type': ''},
'Revision': 6,
'RunOutput': {'ErrorMsg': '',
'ExitCode': 0,
'StderrTruncated': False,
'Stdout': 'hello, world\n',
'StdoutTruncated': False,
'stderr': ''}}],
'NextToken': ''}
Execution ID: e-b7e4f88c-f1b9-45fa-b3b9-34f1287beb32
Stdout:
hello, worldThis time, we can see that our Items key has an array of objects which tells us when our Job was executed, where, and what the output of that Job was.
The code also prints out the results of each execution of the Job along with it’s execution ID:
Execution ID: e-3c81a312-ba8f-4fd9-a1bd-86b0527b2f40
Stdout:
hello, worldIf we had executed our Job on multiple nodes (for instance, using an “Ops” or “Service” Job type which runs on all available nodes), our code would have output the results for each execution in the same Items array.
Conclusion
And it’s as simple as that! Bacalhau offers a variety of ways to interact with your network, whether through CLI tools, the WebUI, or our API and SDK. Each method brings its own advantages, but with the enhanced API interface, developers now have more power than ever to shape and control their workloads.
You can read more about our API on the Bacalhau Docs. There, you’ll find a comprehensive list of endpoints, data structures, and extensive information on building with the Bacalhau API.
How to Get Involved
We welcome your involvement in Bacalhau. There are many ways to contribute, and we’d love to hear from you. Please reach out to us at any of the following locations.
Commercial Support
While Bacalhau is open-source software, the Bacalhau binaries go through the security, verification, and signing build process lovingly crafted by Expanso. You can read more about the difference between open-source Bacalhau and commercially supported Bacalhau in our FAQ. If you would like to use our pre-built binaries and receive commercial support, please contact us!



