


Distributed Queries with SQLite & Bacalhau Project

There are numerous circumstances in which individuals or organizations choose to maintain the confidentiality of their files, rather than making them publicly accessible. In such cases, the ideal approach is to access these files directly on the machine itself, thereby ensuring their security. This is precisely where the strategic application of Bacalhau becomes significant. In this demo, we are going to walk through using Bacalhau on the Azure platform in conjunction with SQLite. We'll guide you through the deployment of a straightforward "Hello World" on a single node, and then extend to querying across all nodes within the network using one simple command.
Follow through step-by-step on how to do this via video here:
Executing Across One Node
To begin with we have installed a number of machines on Azure. We have deployed one individual VM per region and in this example we have 36 different regions. We have written a script display_vm_details.sh to see what is happening inside any particular VM. This script will return the name, location, and IP address of that VM:
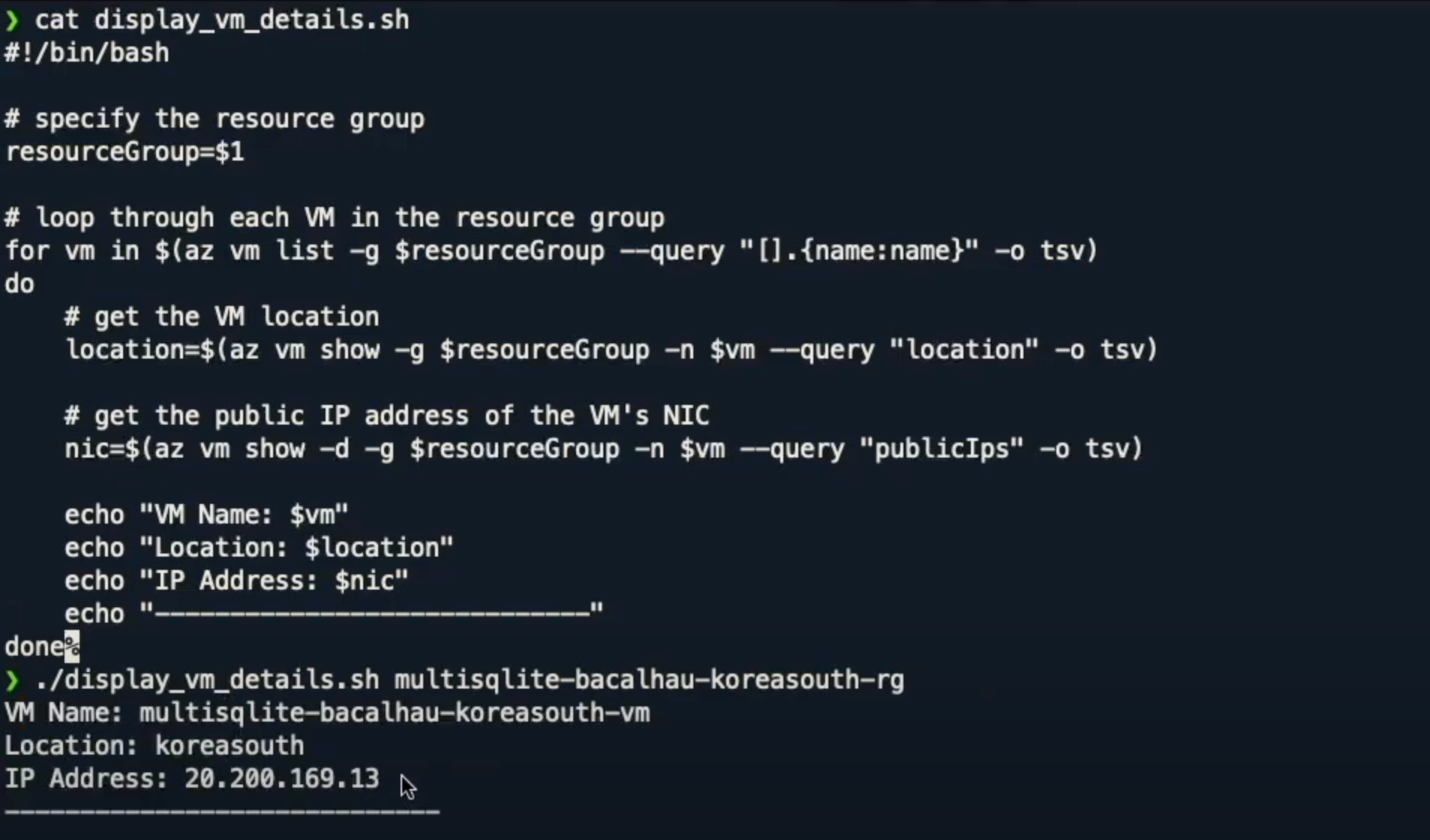
We are then going to look at some of the files inside of that VM. In this demo we are running a SQLite sensor collector and simulating collecting temperature and humidity information.
We have 36 resource groups where we've deployed a single VM, and inside of that VM we have deployed a Bacalhau agent. So, we can now query against the whole network and target a specific region (in this case, France Central) on Azure that we have named and execute a simple “Hello World” command:
bacalhau docker run -s region=francecentral ubuntu echo "hello francecentral"What this does is it goes out to the Bacalhau network and it's finding a machine that matches this particular label and it executes this job against that machine.
We can then use bacalhau describe <JOB ID> to go and look at the results of the job run. There we will see it targeted the region specified and it executed "hello francecentral" in the stdout.
Executing Across Every Node
If we want to execute on every node in the entire Bacalhau network, we can use concurrency:
bacalhau docker run --concurrency=36 ubuntu echo "hello everybody"This command goes out to every machine on the Bacalhau network and executes the same command across every single machine in the network. If you run the following command you can see how many machines your job has been executed against (note, this will output one extra machine representing the header line):
bacalhau describe <JOB ID> | grep JobID | wc -lNow, how might we go about editing and looking at the details inside of our SQLite database.
To show how this might work in production where we don't specifically know the schema, let’s query against that database the specific schema of that SQLite file. In this demo we have written a simple container and published it to do querying against a SQLite database. Then, we mount in the file which is in the database directory on the server and then we execute this script and from that we’ll get the table information. See command run below:
bacalhau docker run -i file:///db:/db docker.io/bacalhauproject/query-sqlite:0.0.1 -- /bin/bash -c "python3 /query.py 'PRAGMA table_info(sensor_data);'"We are looking specifically for what the various columns were as you can see below:

Querying Sensor Data
Next, let's say we want to get into the northcentralus zone, and we want to get all the sensor data that has been uploaded from there. In addition to executing on the command line, we can also execute via a standard YAML script:
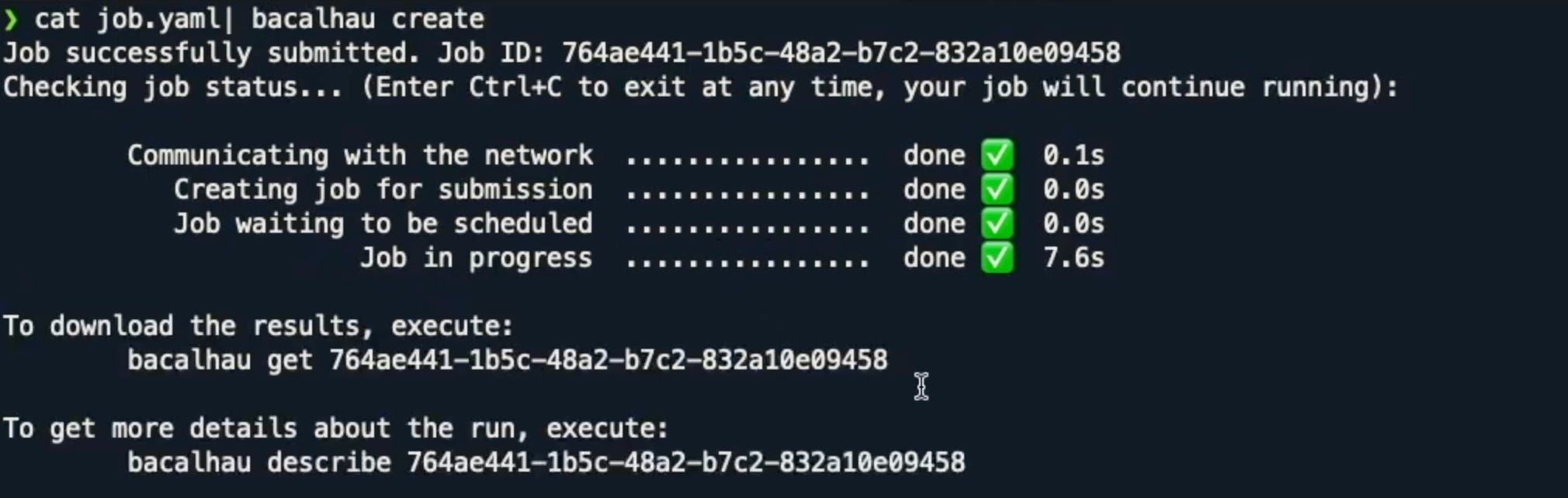
In just a few seconds, it goes and schedules the job to that particular machine in the north central zone and then runs the job against that zone. Again, we can use bacalhau describe <JOB ID> to see the various information, however it has been truncated. Therefore, we want to use bacalhau get to download this information to our local machine in a few seconds. If we then go into the job ID folder we can see the stdout and see the thousands of sensor data logs without ever having to log into the original machine at all.
Sensor Data Everywhere!
Let’s say we want to do something more advanced. For example, instead of querying a single machine, let’s query the entire network. Similar to before, we can do that by using the concurrency flag. In this case, we want to collect the latitude and longitude of where the humidity is over 93:
Spec:
Deal:
Concurrency: 30
Docker:
Entrypoint:
- /bin/bash
- -c
- python3 /query.py 'SELECT * FROM sensor_data WHERE humidity > 93;'
Image: docker.io/bacalhauproject/query-sqlite:0.0.1Similar to before, we'll cat the multi-zone YAML and execute it against the entire network with a single command. This reaches out to every node on the network to execute and query for those particular elements against the SQLight database:

Looking at the data, we will see this command has successfully gone out and collected the overall sensor readings all of which are above 93 humidity. We can now execute any arbitrary query in the same way.
Overall, this demo shows the comprehensive capabilities of Bacalhau as a cross zone, cross-region deployment network. It allows you to harness the potential of local SQLite databases that you operate, while simultaneously maintaining an overarching view of your entire network. Remarkably, all these can be achieved using the straightforward yet robust capabilities of Python.