
🔊 Bacalhau Amplify V1
Announcing the first release of Bacalhau Amplify. This blog post describes development, design decisions, and how you can use it today!


The vast majority of data today goes unnoticed. It is not analyzed, it is not used, it is not understood. One can only imagine the opportunity cost caused by data not being observable.
Look at the image below. Can you see what’s in this data? At first glance, it looks like noise, but it is in fact one of those old-school “if you cross your eyes enough” images that has a number in the middle of it.
Institutional data has this exact same problem. If it’s your own data stored in (for example) blob storage, you don’t really know what’s in there. If we’re talking about IPFS, again, it’s a vast ocean of “je ne sais pas.”
Similarly, (most) people still don’t know about Bacalhau. This incredible decentralized computing resource. One way to improve traction is to provide simpler onboarding routes.
So what if we could build a tool that provides a pleasant onramp to Bacalhau and also solves the existential data crisis? What if we could build a tool that could scan data? Find data? Analyze data? Organize data? without any human interaction at all? What if we could build a tool that could automatically explain, enrich, and enhance your data?
[pause for dramatic effect]
Introducing Bacalhau Amplify
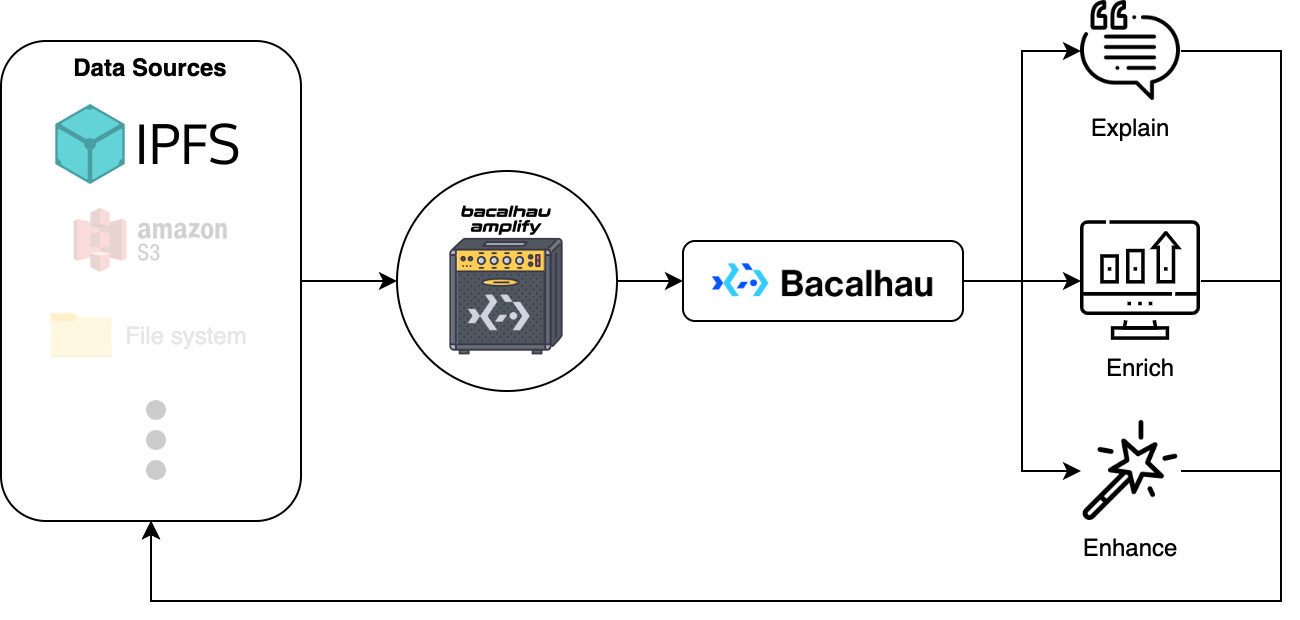
Amplify is a Bacalhau project with the following goals. Given your data, it will automatically: explain, enrich, and enhance.
We want to explain your data by exposing metadata like mime types, and file statistics. Describe what's in images and what's in videos, present information about structured data, and more.
We want to enrich your data with simple reporting tools, and imputations. Add additional information when relevant, validate your structured data, test your image data, and more.
We want to enhance your data by converting it to different formats, transcoding videos, compressing, resizing, augmenting, and more.
The key here is "and more". We’ve developed a system that is both lightweight and extensible. Developers can easily add new ways of working thanks to clever abstractions.
Design Decisions
Early on, we decided that we wanted to leverage the Bacalhau network as our main computational capability, so we made the decision to use containers as the main unit of work.
For the backend, we decided that continuing to use Go was beneficial from a maintenance perspective because the wider Bacalhau team is already Go wizards. The front end is written in React for the same reason and bundled into the Go binary thanks to Go’s awesome embed package.
At this point, we made our first difficult decision. We knew that we needed to build execution graphs, i.e., combinations of Bacalhau jobs. So we initially thought about using a dedicated graph orchestration framework or service like Airflow. But after mulling it over, we decided that we’d roll our own graph executor. We knew that we didn’t have any requirements for complex graphs, and we were keen to reduce the dependencies. How hard can it be?

One of the most interesting challenges was figuring out how to pass data between dependent nodes. In Kubeflow, you have a really nice abstraction, but it ends up being quite simple.
We tightly specified the input and output interfaces of the jobs, ensuring that jobs iterate over all input files and directories, and write their results to a consistent location. We use `stdout` to communicate metadata, and `stderr` to report logs. This has worked really well so far, mainly because it’s so simple and prevalent.
Architecture
The codebase consists of a few interesting abstractions that are designed to be extended. Let’s start from the bottom.
A job is abstracted by an Executor interface. It consists of rendering and execution functions. Currently, we have a Bacalhau and an internal executor. But it would be really easy to add more (like a local Docker executor for development).
Jobs are then encoded in the config.yaml file. This is a simple but opinionated location to declare jobs and workflows. Jobs require unique IDs and must include the necessary configuration information (like the Docker image).
Workflows (the execution graph) are also defined in the config.yaml. This is a list of nodes in an execution graph with input and output definitions. The graph is built by declaring parent nodes as inputs. One interesting feature here is that you can specify a predicate, which is a regex that must be present in the input’s stdout. We use this internally to skip nodes that don’t have a mime type of image/png, for example.
Finally, at the top, we have triggers. These schedule a new execution of a workflow given an IPFS CID. Currently, we support API triggers or new IPFS declarations from the excellent ipfs-search.com API.
What does this mean? This means we’re automatically explaining, enriching, and enhancing all data on the IPFS network!
So far we’ve run 750k jobs and processed 150k CIDs.

How To Get Started
We’ve written some user documentation on the Bacalhau website, so please visit the Bacalhau documentation if you want to learn more.
But here’s a sneaky peek. Take a look at the hosted user interface on: http://amplify.bacalhau.org/
How To Extend Amplify
We’ve designed Amplify to be extensible. Most of the key elements are wrapped behind simple interfaces and are just screaming out for help.
You could add new job types. We’re missing quite a lot right now and you could really add value by developing new types of workloads. For example, video transcription, json data reporting, and many more besides.
Once you have a new job, then you can create new workflows. Maybe add the job to an existing one, or maybe develop a whole new flow.
If you’re unsatisfied with executing on Bacalhau nodes, you could write a new executor. It’s easy to add new types. A local Docker executor, anyone?
And finally, you can add more triggers. We originally set out to have more triggers, but we found that the ipfs-search trigger exercised enough of the system so stopped there.
Demo Time!
Now I’m going to hand it over to my colleague Enrico Rotundo , to deliver some dashing demos!
Each of these demos was initiated with a CID representing a particular type of data. But remember that Amplify will automatically run the appropriate workflows for a particular mime type.
Raw Text Summarization and Explanation
In this demo we look at the raw text type. The text summarization workflow is triggered and provides a nice summary of the content of a CID.
Batch Image Resizing and Object Detection
In the following demo using a CID containing images, we look at the batch resizing and object classification workflows.
Batch Video Resizing and Object Detection
Finally, the CID in this demo contains videos which flows through video enhancement and object classification workflows.
Help Us to Help You
Thanks for your interest in Bacalhau Amplify. We’d love to receive your feedback on our work. Is it useful to your projects? What pain does it solve? Can you make use of it? What’s preventing your adoption?
We also appreciate all the public support we can get. Tweet away and tag @BacalhauProject, and star the Amplify Github repository.
Below we present all the resources associated with Amplify:
Documentation: https://docs.bacalhau.org/related-projects/amplify
Repository: https://github.com/bacalhau-project/amplify/
Developer Documentation: https://github.com/bacalhau-project/amplify/tree/main/docs
Hosted Amplify Service: http://amplify.bacalhau.org/